ChatGPT Code Generation Capabilities: a case study of topic modeling in python

Introduction
What follows is a description of a few weeks interaction with ChatGPT using it as a sort of coding assistant for a research project in Topic Modeling that I am currently working on. Topic Modeling is in and of itself a semi-advanced research area within the Natural Language Processing (NLP) discipline that leverages its own unique machine learning and NLP techniques to parse through raw text (natural language) files and come up with summary topics that are reflective of the text itself that can assist users in navigating through, or searching on, said text.
Generally speaking, Topic Modeling is a fairly well understood problem in NLP but with many variations and techniques that can be applied, depending upon the nature of the language being processed or the use case upon which we are generating the topics on said text.
What follows is an introduction to the ChatGPT tool itself (very brief, many more comprehensive introductions can be found and are referred to) and some information on how it was constructed (how it was both developed and how it was trained) so that we can come to a better understanding, within the context of code generation specifically, where ChatGPT’s capabilities lie and how it can best be used – primarily in gains for productivity.
We use images throughout, not just from output of ChatGPT and of working code, but architectural images as well, from sources that are noted with images. Picture is worth a thousand words they say and in the event that you do get all the way through the narrative here, you should leave with a better understanding of language models and where they sit in the Ai and NLP domain from a research and development standpoint, where ChatGPT sits within this landscape, and how it can be used to (substantially) increase productivity for people that write code either as an amateur (for whatever your reasons are) or as a professional (software developers or engineers).
It’s worth noting here, and as a writer and student this is both relevant and important, all of the actual ‘writing’ in this paper has been done by the author itself and where ChatGPT has contributed, which is only in the areas of code as illustrated in the figures throughout, it is duly noted.
Locating ChatGPT in the NLP Landscape
In brief, ChatGPT is a question-and-answer chat bot that was developed by a company called OpenAI and launched in November 2022. It was developed using OpenAI’s GPT-3 architecture (GPT standing for Generative Pre-Trained Transformer), but has predecessor (language models) upon which its development is based. This particular version of ChatGPT is known as an autoregressive language model which is essentially a fancy way to say that it uses advanced statistical techniques to determine what the best possible answers are to given, prompted, questions.
What first and foremost must be understood about ChatGPT as an AI tool, a fact that is very often ignored or misconstrued in the popular media, is that as software it is fundamentally no different than all other software programs in the sense that a user provides input and the software provides output. What is special about it, as is special with many of the modern ‘language models’ that have been developed, is how sophisticated the software is in determining what the ‘output’ should look like, given a set of inputs which in this case are of course the user ‘prompts’ but also the vast training data that have been made available to it, along with the training techniques used by the developers, which both in turn determine both how and what it is that the software deems ‘correct’ – or more aptly put perhaps ‘optimal’ output.
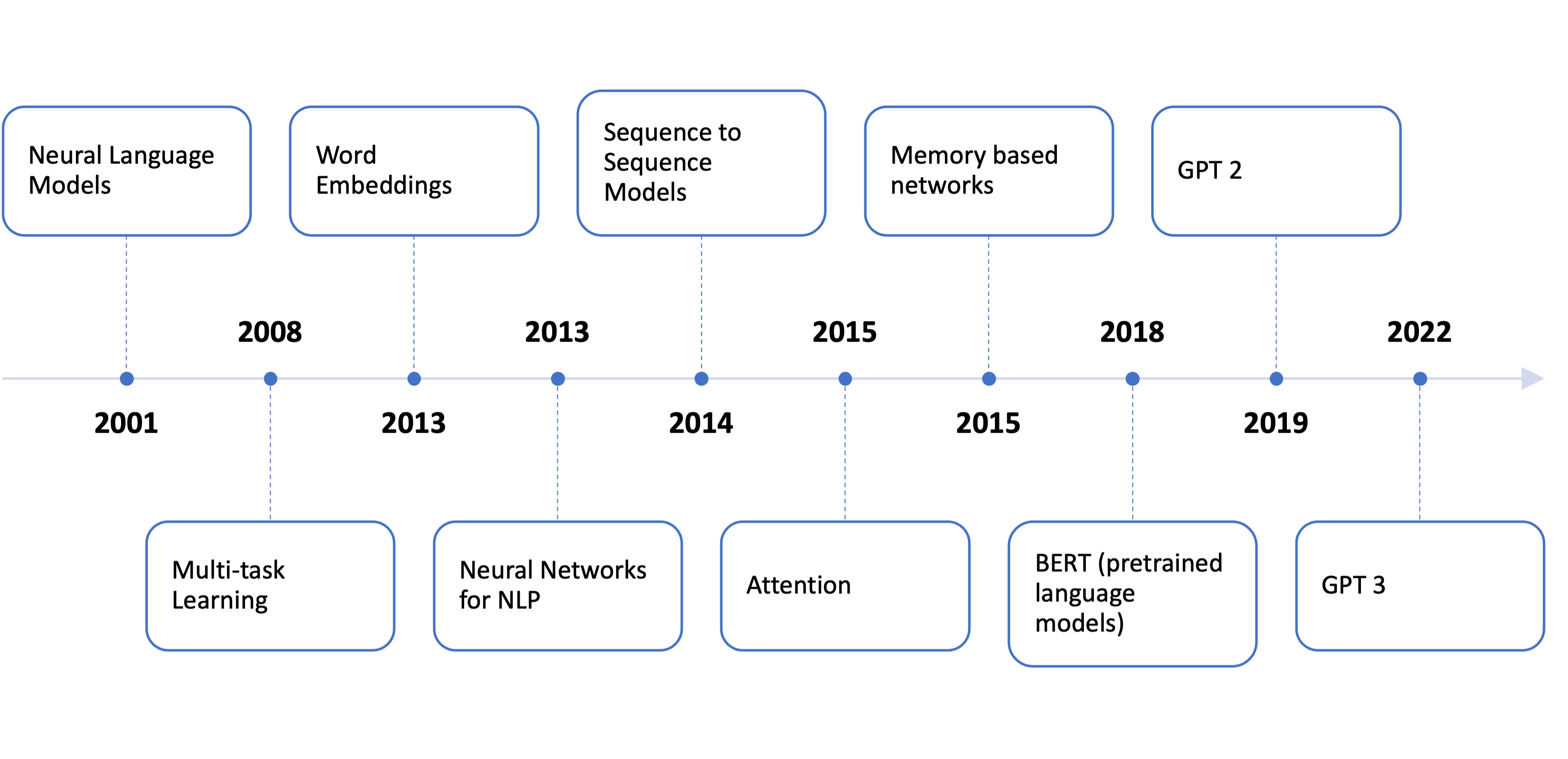 Figure 1: Evolution of Language Models
Figure 1: Evolution of Language Models
The power of these language models that are beginning to take hold of the technologically savvy consciousness throughout the modern world is based upon three fundamental pillars:
1) proliferation and availability of data (natural language),
2) availability of computing resources at reasonable, or affordable costs, and
3) existence of efficient algorithms and architectures (deep learning, neural nets)
Without all three of these there would be no language models that were available to the general public that were as powerful, and useful, as something like ChatGPT. This revolution is a long time coming no doubt but for sure it is starting to gain some momentum with respect to both utility as well as availability. ChatGPT is everywhere in the tech news right now and rightfully so because it undoubtedly reflects the next big revolution in computing since Internet Search (Google). In some respects it could be called a sort of Search 2.0 but then again it’s capabilities go well beyond simple search and even well beyond Google search capabilities which itself goes well beyond simple Search.
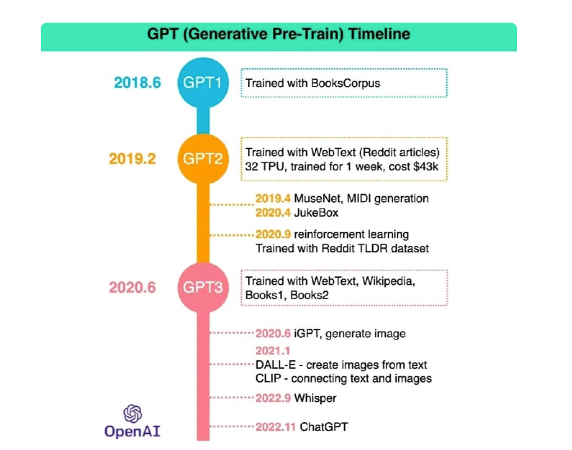
Figure 2: GPT Development Timeline
Much of the technology that underpins ChatGPT – the tools, techniques, libraries and infrastructure – has been in development over the last few decades in the domain that is referred to in the research community as Natural Language Processing, or NLP. ChatGPT fits squarely in this domain, but it’s unique and innovative with respect to the ease of use of the interface itself as well as its ability to store and save ‘conversational context’, something we have not seen done well before with previous language models. ChatGPT has no doubt set a new bar with respect to how we expect these language models to behave and what kind of (intelligent and utilitarian) output we expect to get from them.
There have been many advancements in the NLP domain in the last few years, building off of years of research and development into various deep learning techniques (using neural networks) to optimize these language models for text prediction ultimately – optimizing the problem of based on a given input what is the best possible output. This is the fundamental problem, or challenge, of chatbots and how this is solved for can in many cases be domain specific.
For a language model that is as generic as ChatGPT, one must not only ensure that it is trained on enough material to cover (from a scope perspective) the broad range of knowledge that it will be asked to speak to, or be prompted with, but that it is tested and trained on enough use cases such that it is effective in how it behaves – effective being measured not only as a metric on how good, or accurate, its responses are generally but also that it handles corner cases from a usability perspective to make sure that it filters out prompts that are abusive or malicious.
The usability and testing portion of the development of the product cannot be overstated and these capabilities, along with the scalability and performance aspects of the tool given how quickly and widely it has been adopted since its release, have no doubt accounted for much of the development of the product since its ‘beta’ release last November.
How was ChatGPT Built?
The best way to understand how the tool works is of course to use it, so keeping with the narrative of the current paper we will ask it how it was constructed and how it was trained and see what kind of answers we get. After a few refusals to answer my detailed development and architecture questions I did get ChatGPT to answer finally and provide some information on how it is that it thinks (using the word ‘thinks’ quite broadly here) it was developed.
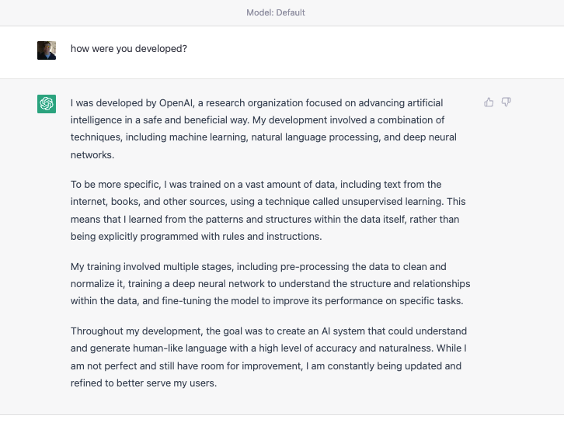 Figure 3: Prompting ChatGPT on how it was developed
Figure 3: Prompting ChatGPT on how it was developed
While light on detailed architecture, proprietary secrets and all no doubt, we do get a pretty good explanation of who and how the tool was developed, which is precisely what we asked. It’s purpose in a way can be extracted from the response as well which, as far as answers go, is undoubtedly not only informational but also in a sense philosophical.
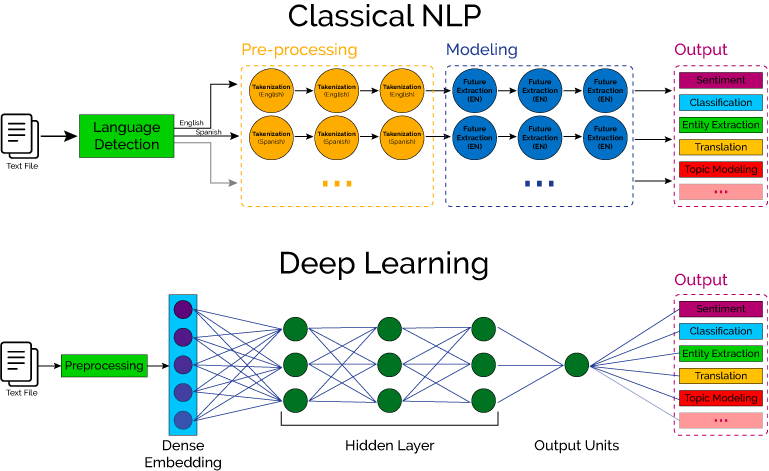 Figure 4: NLP and Deep Learning Architecture
Figure 4: NLP and Deep Learning Architecture
This is a great answer actually, and one wonders if it ‘learned’ this answer or if it was directly coded into the system given how common of a question (prompt) it most likely is. The techniques it describes, as well as the data normalization process as well, are standard techniques and algorithms that are necessary to solve most, if not all, Natural Language Processing (NLP) types of problems in AI. Data must be parsed and normalized so that the ‘machine’ can understand it, and then the models are tuned as they go to optimize ‘results’, depending upon how you are measuring results.
In this case, ChatGPT development does involve human feedback so this input definitely guided its development. We can actually see the thumbs up and thumbs down icons on the response that allow for user feedback in the current interface. If you select one of these, a window pops up that asks you what an ideal answer would look like actually, so the model is continuously learning.
Not only is the underlying architecture of ChatGPT unique however, the way it was trained is also unique, using both supervised and reinforcement learning techniques to fine tune its answers and optimize its output. Let’s see what ChatGPT has to say about how it was trained, using a separate session here that originally refused to answer how it was built but upon further prompting revealed how it was trained.
 Figure 5: Prompting ChatGPT on how it was trained
Figure 5: Prompting ChatGPT on how it was trained
A fairly generic description of the training methods that were used as you can see but we can see here some of the limitations of the tool itself – it’s a language model so it doesn’t deal with, nor can it generate or pull form, images or pictures. There are other AI tools available that work exclusively with picture generation actually, some of which are from OpenAI, but these capabilities have not been built into ChatGPT (yet).
A good pictoral description of the training methods of ChatGPT, which in and of themselves are unique and groundbreaking, can be found on OpenAI’s website.
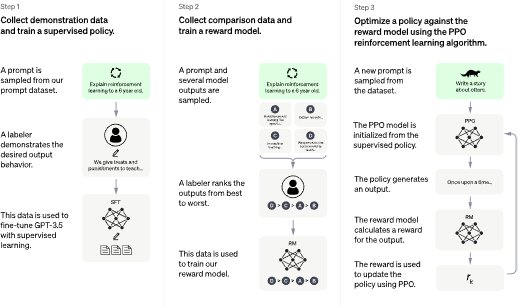 Figure 6: ChatGPT training method
Figure 6: ChatGPT training method
One should be able to see here, even if you don’t fully understand or appreciate the techniques that were involved to build ChatGPT and optimize its output, is that it is not only the architecture and tools that were used to build ChatGPT that are significant and groundbreaking (and arguably given the language model landscape they are not so much) but the way in which it was trained and how that training was fed back into the underlying ML model which sits behind its groundbreaking capabilities which have underpinned its popularity. The way in which this feedback from training was used to optimize its output is just as innovative as the way the model itself was constructed from a coding or development perspective, because fundamentally ChatGPT, and all language models really, leverage the state of the art in Machine Learning techniques, techniques that are rooted in what is typically referred to as Deep learning now, which is rooted on the idea of neural networks, a field which in and of itself is extremely technical and extremely broad in its applicability – across NLP and other AI disciplines.
Code Generation Capabilities
Because ChatGPT is a language model, meaning that is it designed to accept text (natural language as it is referred to in the research literature) based prompts and return text based prompts. It has support for at least 90+ languages but English is where it most proficient not surprisingly. Furthermore, again because it has seen and been trained on such data, ChatGPT also supports a variety of programming languages from Python, to C to shell script, to PHP to Java.
This means that if you program in any of these languages (and there are more), you absolutely should be working with ChatGPT to quick start your code, build libraries or other programming specific scaffolding, or even in some cases have it help you debug your code or identify problems with it – the latter being a fairly advanced topic that is very much specific to the problem at hand.
We can already see applicability for example in integration with development environments for auto-code generation with a ChatGPT plugin for VS Code available, one of the most popular coding development environments from Microsoft . This is an immensely powerful productivity tool for programmers, but even without the integration into an IDE (integrated development environment), ChatGPT can itself provide very useful and capable code for a variety of application development problems.
Note again that in order for ChatGPT to be able to generate good, working or workable code in any of these languages it must have been specifically trained on code, working and functional code, from these specific technical language domains. Clearly, given how proficient ChatGPT is at this task, in the broad set of languages that it supports, indicates that this is no doubt one of the uses it was designed specifically for.
Top see an example of how this relationship could work, or might work, and an example of how effective ChatGPT can be in generating code as well as where it starts to hit its limitations, we will use a current research problem I’m working on in the NLP domain itself, in the area known as Topic Modeling, an advanced but nonetheless fairly well understood problem in NLP which is the creation of, through the analysis of text (again NLP), the automatic (unsupervised) generation of topics from a document or series of documents (referred to as a corpus).
Note that the code output and examples given below represent a series of sessions with ChatGPT over several weeks during my research and so do not all represent the Q&A in a single session. It is worth noting however that ChatGPT, at least in the professional version, can preserve a conversation and context for several days, as long as the browser page remains open and cookies are enabled it would appear.
File Preprocessing
Every NLP problem starts with the challenge of taking raw text and getting it into a format (typically scalers of matrices, matrices that can be very sparse when representing a textual corpus) that a machine learning engine can understand. Our problem is no different and we work with a single, large text in the philosophical domain to which we have access to the text data itself. We have the raw text file on disk but we don’t have it parsed at all, or cleaned of stop words or other special characters for example, and as such we need to pull apart the text and normalize it so to speak. And this is where our narrative begins.
We start with a fairly generic prompt, which asks ChatGPT to divide up a large text file into chapters on disk, a task that would be pretty common in the NLP domain where first and foremost one needs to extract and load the data into a format that the underlying machine learning algorithms (upon which NLP is based in fact) can make sense of, and ultimately predict and perform tasks on. ChatGPT quickly outputs some sample code, in python as requested, and with a few easy modifications, it can be loaded into an IDE (integrated development environment) and does essentially what we have asked.
 Figure 7: ChatGPT File Chunking
Figure 7: ChatGPT File Chunking
So far so good. As our next preprocessing task, we take the output of the first function above and we ask ChatGPT to take a series of text files in directory on disk somewhere, and read the files and output their titles, the titles of each chapter being the first line of text in the file itself. The full prompt and response interaction can be found below.
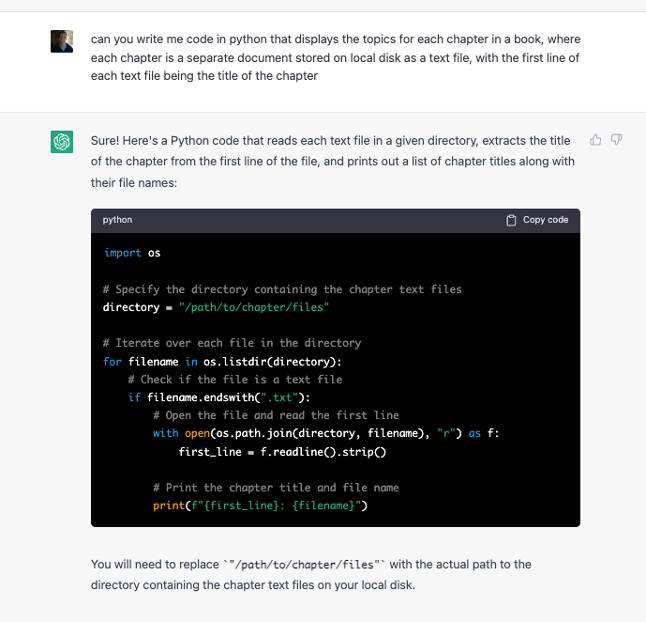 Figure 8: Parsing Text Chapters from Disk
Figure 8: Parsing Text Chapters from Disk
This code too actually works, ie if you run it in a python environment with the right libraries installed and configured that code (once we change the path to the directory) will in fact pull the chapter names from each file.
Note the helpful hint at the end that provides some explanatory remarks about the code, this is one of the unique characteristics of ChatGPT’s code generation capabilities, along with its ability to keep context throughout the length of an interaction. There is no doubt an element of ‘understanding’ here at least from the context of what the code does, its function, and how it must be modified in order to ‘work’ as it were.
So as we can see, with respect to file loading and parsing activities, ChatGPT seems very well equipped to handle these for us in a fashion that is both efficient and most certainly time saving as some of these types of coding assignments can take time to get right.
Building a Topic Model using Latent Dirichlet Allocation (LDA)
We certainly don’t have fully functional code yet to build out Topic Model though, but the good news is that, and one of the unique features of ChatGPT in fact, it stores the state of the Q&A session so it knows what you asked and it knows what it responded and can revise and refine outputs accordingly. We will see this capability demonstrated in short order as we continue build on what we have already put in place.
What we want is to derive a set of topics from the chapters of the text that we have parsed automatically, or in an ‘unsupervised manner’ to use AI and MLP speak. There are a variety of ways to do this but this most common is using a technique called Latent Dirichlet Allocation which is a statistical “grouping” algorithm of sorts which was originally devised in the field biology (evolutionary) but is also utilized in NLP to come up with a group of topics associated with a given corpus of documents.
This is what we want ChatGPT to do for us next, and is more or less a well understood problem in Python online so we would expect a good result from a prompt that is specific enough, and technical enough, to point ChatGPT in the right direction.
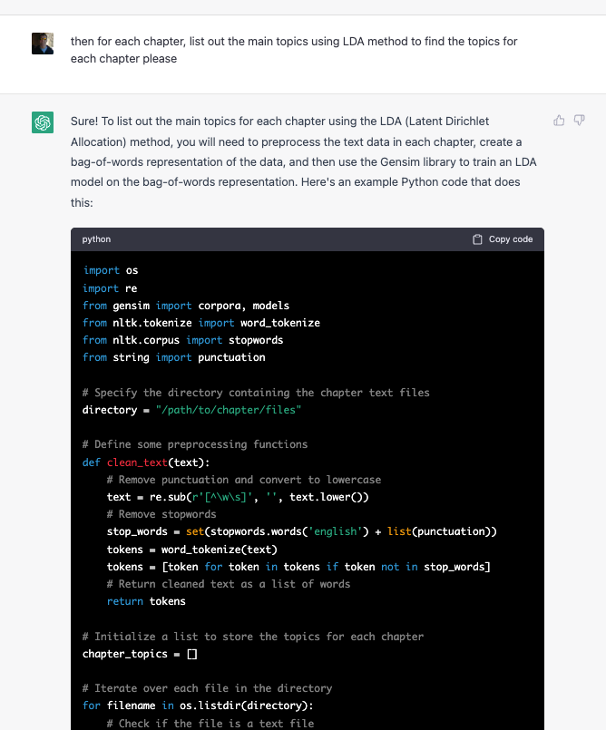 Figure 9: Topic Modeling Prompt 2 – LDA using Bag of Words
Figure 9: Topic Modeling Prompt 2 – LDA using Bag of Words
 Figure 10: Topic Modeling Prompt 2 – LDA and Bag of Words Continued
Figure 10: Topic Modeling Prompt 2 – LDA and Bag of Words Continued
We get solid, well-organized output here that builds off of the code from the same session and extends it. The code is clear, variable names are explanatory and comments are inserted in the code in appropriate, and meaningful, places. Furthermore, we get the explanatory text at the end as well which is very helpful – certainly to the novice programmer who is looking to make use of the code output.
All the necessary imports are here, with the reference for the directory as well as the code needed to clean the input and prepare it for model optimization using LDA. The code goes on to actually pull each file from disk, prep the file (using the bag of words method which essentially encodes each word with number from a given dictionary and then stores each document, chapter in this case, as a matrix of words essentially) and then feed the machine prepped data into the LDA algorithm for processing and Topic Modeling generation.
Leaving aside the intricacies of LDA and Topic Modeling techniques, this code (once input in an IDE with a few minor adjustments) actually works, as can be seen from the output below:
 Figure 11: Topics Extracted using ChatGPT generated code
Figure 11: Topics Extracted using ChatGPT generated code
What tells us that this is a good working code base here is ultimately whether or not the Topics that it outputs are in fact representative of the chapter(s) it is using as input. Given the text itself, the chapter title that is pulled from the raw text file, and the fact that I wrote the text myself, I can say that the algorithm does in fact work in a manner that is certainly satisfactory for a first pass on a text of this size for this type of granularity, or level of abstraction you might say, given the (chapter) text of the corpus that we are using for testing.
This works and requires little or no coding on my part to get here. If I had done the coding myself, even pulling from online sources, it could take me hours or even days to get the code to this place. This is a huge time saver.
Pivoting from Bag of Words to TF-IDF Representation
There are different representations of text however, and the bag of words model, where you just basically construct matrices of word counts and associate each with a document (or in our case a chapter), is most definitely the simplest of models. Another more sophisticated word representation, one that is used quite often in NLP circles, is the Term-Frequency, Inverse Document Frequency (TF-IDF) metric which, for each word or token in the text, score the term by importance relative to the document (term frequency) and the corpus itself (inverse document frequency) as a sort of relative importance barometer of a given term within the context of the document and corpus itself. A natural next question, a more sophisticated question, to ChatGPT would be then, well can you do the same thing using a TF-IDF model versus simply a bag of words model and then we can see what that output looks like.
We now use the same session context and prompt ChatGPT to make the modification in the code and we get the following:
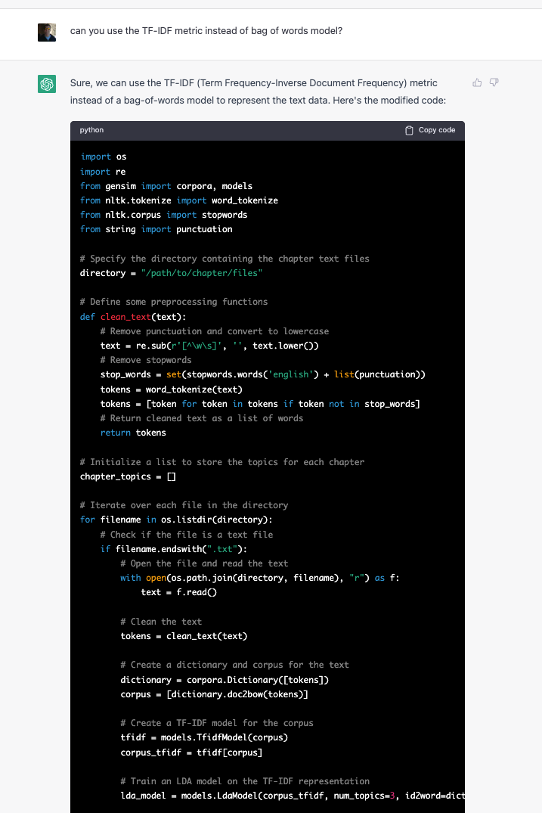 Figure 12: Topic Modeling code gen using TF-IDF Metric
Figure 12: Topic Modeling code gen using TF-IDF Metric
You can see that the prompt is short and to the point, and ChatGPT does in fact store and keep the context of the “conversation” that is being had, and its output follows the same flow and terminology of previous output along the same channel so to speak. It inserts the new code into the appropriate spot and names it as you would expect, modifying the downstream LDA model construction to use the tf-idf model rather than the bag of words one we used previously, although interestingly it left the old code in even though it wasn’t being used.
While this code does in fact ‘work’ in the sense that it runs and it generates the different representation of the text as we want it to, the output it generates is nonsensical, illustrating that while ChatGPT knows well enough to follow specific prompts and instructions to generate text, it lacks an understanding of a) what the relationship is between the ode itself and what it would output and b) an understanding (a loaded term in AI but we use it here) of what it is we are trying to do with the code itself.
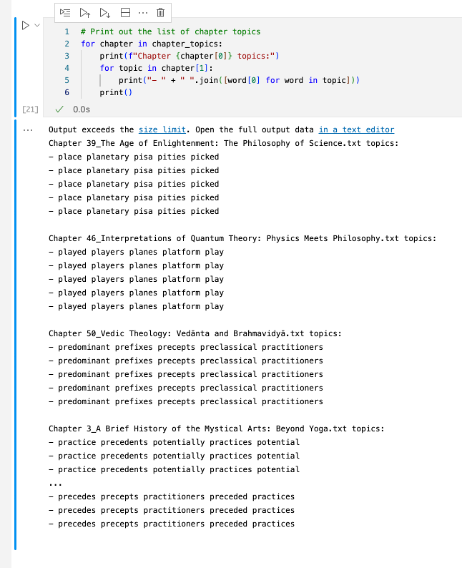 Figure 13: ChatGPT Topic Modeling code using TF-IDF text representation
Figure 13: ChatGPT Topic Modeling code using TF-IDF text representation
As one should be able to infer from the title of the chapters which is printed on the output, and the output of the initial run which used the bag of words representation of the text, these topics are not very reflective of the text itself so in that sense the code here, in the TF-IDF example, has a fundamental problem with it – one that ChatGPT is clearly not aware of.
When I ask it why the output is different, it does come up with what one might refer to as an intelligent response.
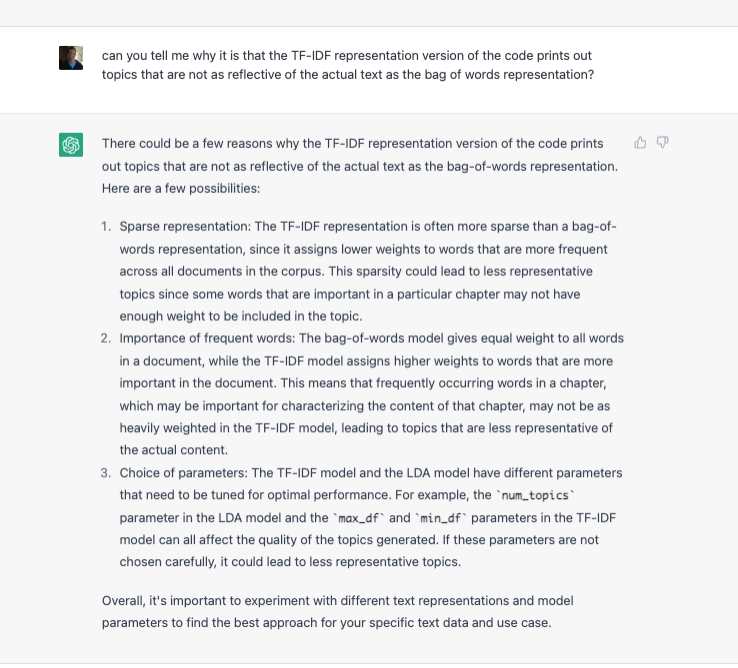 Figure 14: ChatGPT on difference between TF-IDF and Bag of Words Text Representation
Figure 14: ChatGPT on difference between TF-IDF and Bag of Words Text Representation
So of course we ask it to fix the code and it does in fact attempt to do so, with a fairly detailed and sound explanation for what might be the problem. However, despite its (our) best efforts, in a series of back and forths with ChatGPT (which I will not output here for the sake of brevity), my repeated prompts and queries related to the problem with using the TF-IDF representation does yield a series of attempts to ‘correct’ the code but each one of them fails to modify the output significantly, indicating that there is clearly something fundamentally missing from how it is computing the topics from the underlying text with the modified representation.
This is a classic problem with building, and debugging, ML models however – getting the input data and underlying algorithm tuned just right so that the output is what is expected, ie makes sense – so its fair to say that that part of putting all the pieces together to make a program work end to end still lays beyond what ChatGPT is capable of. For now.
Analysis & Summary
In this case study if we may call it that, we take a look at ChatGPT’s capabilities with respect to outputting python code related to the NLP domain itself as a function of specific, technical inputs from someone who is familiar with the field and familiar with how the underlying models themselves are constructed, and ultimately coded. We look at how ChatGPT specifically handles the tasks related to the pre-processing of texts, the feeding of said data structures into a specific underlying model (LDA) with a specific expected output in mind against a text that the author is familiar with.
When it comes to file parsing, text manipulation and other what you may call standard, well understood coding problems or tasks, ChatGPT is very good at providing answers that are almost correct, or very close to being able to be plugged into a compiler or development environment and working as expected, ie producing the desired result. This ability can be leveraged by any programmer to provide what you might call the necessary scaffolding of any computer program – providing arguments, building basic interfaces, validating input in a certain way, etc.
When we venture further into problem solving however, especially innovative problem solving, we enter into a very different area however. ChatGPT can and does provide answers, in many (or most) cases that are in the problem domain we are solving for, the ability to get direct answers that function as we expect becomes quite limiting. In these examples, as has happened with several use cases, ChatGPT can even get somewhat confused and lacks what you might call an ‘understanding’ of what the problem is that we’re trying to solve for. This is despite the fact that ChatGPT, and again this quite revolutionary, has the ability to recall context of a message thread over time – in fact it even can save states over the course of a few days as I’ve had dialogue with ChatGPT on one problem over several days and the context, as well as its ability to revise and modify output based upon further prompts, remains in tact.
This is what we might expect however, given the way that ChatGPT – and generally all language models – work. That is to say, it looks for optimum outputs based upon a given set of inputs, given the data it is trained on. Our inputs here are prompts, and given the way it has been trained and what material has been used for training (leaving aside the guardrails that have been put in place to avoid abusive or malicious outputs), we would expect that – at least as of 2021 which is the termination date of its training material – that for well understood problems, well understood and well documented problems, discussions, analysis or textual descriptions and documents you could say, ChatGPT will find the optimum output based upon the inputs that reflects quite clearly what it is you are getting at, what you are asking.
However, consistent with this methodology and mechanisms, we also would expect that when we prompt ChatGPT to solve for problems that are less well understood, have not necessarily been solved for yet, it begins to leave the reservation so to speak and venture into areas that while seem like they make sense, in fact – at least from a functional programming standpoint – in fact do not. Several cases of Topic Modeling and Ontology Learning areas that are current focus of my research it will provide seemingly reasonable code to solve for the problems that I am prompting it with but the code doesn’t work and doesn’t work fundamentally and when ChatGPT is prompting to correct it, it does not do a good job doing so and ultimately leads to a sort of continuous loop of code changes and iterations that it recommends but that ultimately doesn’t get any closer to solving the problem.
But this is in fact what we might expect from these types of models and it speaks to their best uses in fact. That it should be used to facilitate building and constructing ideas, code or other forms of text for problems that are well understood and already solved, in which case you will have a very high likelihood of ‘correct’ answers, whereas once you start to venture into areas that are less understood, that are areas of current research or problems that have not been solved before, in this case one must take the output with a grain of salt so to speak – it may have kernels of ideas that can be useful but this kind of output needs to be checked, validated and analyzed by an expert of sorts, or in the case of code very well tested, in order to ensure that the task at hand is indeed being solved for.
Its perhaps fair to then generalize that for coding tasks specifically, ChatGPT is best used for putting together existing solutions or paradigms for a specific context, rather than asking it to solve problems that are either not well understood or haven’t been solved before – again specific to utilizing ChatGPT as a sort of coding assistant to optimize its output utility. It’s also important to note that the data that (this version) of ChatGPT was trained on was from 2021 so right there we have a gap in knowledge so to speak – any new paradigms, algorithms or research papers in the area of interest would not be known to ChatGPT and therefore likelihood of error would be high.
Having said that, its never a bad idea to experiment with the tool for a given problem to see how it approaches it, or see what kind of code it outputs, some of which may be useful even if the code itself doesn’t work the way you want it to. To that end, it most certainly represents an aspect of programming that could provide indispensable for programmers going forward, a sort of programming assistant that is mostly right (for easier problems) and mostly not so right for harder, or again less well understood, problems but a valuable assistant regardless.






Leave a Reply
Want to join the discussion?Feel free to contribute!